
- 6 min. reading time
Searching an internal Knowledge Base with OpenAI and Azure Cognitive Search
Contents
Looking for information in an internal knowledge base like Confluence [1] or similar applications can sometimes feel like a game of hide and seek. You know the information is there somewhere but finding it can be a challenge. Whether you're a new employee trying to navigate the system or a seasoned pro who still can't seem to find what you're looking for, the struggle is real. In fact, the struggle is so real that knowledge workers spend up to a fifth of their time searching for and gathering information [2]. In addition, for people starting in companies in highly regulated environments like the aviation industry, it can be difficult to access the answers to their questions simply due to the amount of information available. Wouldn't it be great, if we could reduce this time and end up regularly with less than one full working day of search each week? This could enable teams to take on faster, better-informed decisions and spend more time working on solutions.
With the rise of tools like ChatGPT [3] or Bing Chat [4], we've now all learned how generative AI has the potential to revolutionize the way we interact with technology. A Large Language Model (LLM) can now understand and respond to questions in a way that is similar to how you would ask a well-informed coworker. However, it is important to note that a LLM is limited by the information it was trained on. While it can answer a wide range of questions based on what it has learned, it is not able to access internal company knowledge or provide responses that are beyond its training. When using ChatGPT plugins or Bing search, you are already able to see how this limitation can be overcome to some extent. Along with your chat, a web search is integrated which feeds the results into the prompt along with the question before providing a response. However, while this might help with answering questions based on more recent information, it still does not help in your daily game of Confluence articles hide and seek. ChatGPT and Bing search do not have access to the internal knowledge base of a company for good reasons.
In this blog post, we'll take a look at how we at Volocopter started to build our own LLM enhanced chat to provide answers based on our internal documentation to try and win the game of knowledge-based hide and seek.
Data Quality is Key
When it comes to using LLMs to answer questions on internal information, data quality (as usual) is the key for success. The accuracy and completeness of the data you feed into the prompt will directly impact the usefulness of the responses you receive. Poor data quality can lead to incomplete or inaccurate responses. Obviously, this will be frustrating for users. For us, Confluence serves as a companywide knowledge base for information about all our departments and providing employees with the latest company updates. Additionally, every department owns their own space for the documentation of team and project specific information. Therefore, every team is responsible for keeping information up to date and decides what documentation to keep. Naturally, this leads to outdated information as well as some pages of documentation are more governed than others. Most likely, this is a situation everyone knows from their own internal knowledge base as well. For a LLM based chat it is important to note that feeding this information into our LLM chat could lead to outdated answers as well.
Therefore, it was important for us to spend time on the evaluation of the level of quality of the documentation before blindly blasting it into the prompts as context.
In webmanuals [5], a document management system we use to edit, review and distribute our aviation specific documentation, each document change is thoroughly reviewed which leads to a high quality of data for every document. Therefore, all of the documents were already well prepared for an integration into our application.
Preparing documents for search
Now, let us jump into the fun bits and look at how we built the internal knowledge base search. At the beginning of every data application, you find the part that extracts, transforms & loads data so it ends up in a structure which can be utilized by the application.
For our documents, we load those from Confluence and webmanuals. As a first step, each document is split into sections. Each section is cut out of the document with a fixed maximum length where we always extract full sentences and try to keep bits that semantically belong together in one section to the extent that it is possible. This will assist us in ensuring that the quantity of text we provide to the LLM is sufficient to address the query while minimizing irrelevant information. Using a section based approach rather than entire documents reduces the number of tokens when feeding the information into the LLM, resulting in quicker responses and lower costs. Along with the section's text, we add some metadata. This includes the page number from the original document and the source link to Confluence or webmanuals. By adding this information, we can always refer to the original document in the form of citations in our chat.
Once each section is prepared with its text and metadata, it is uploaded to Azure Cognitive Search [6]. In Azure Cognitive Search, we have created an index which stores all our document sections along with the metadata. Querying this index shows us the top n results for all relevant documents for the search term. For example, if we would search for "writing a blog post" it would show us the top n sections that are related to writing a blog post for Volocopter along with information about where to find the original document. Afterwards, we only need to include this information in the prompt for the LLM as context information to answer the user's question.
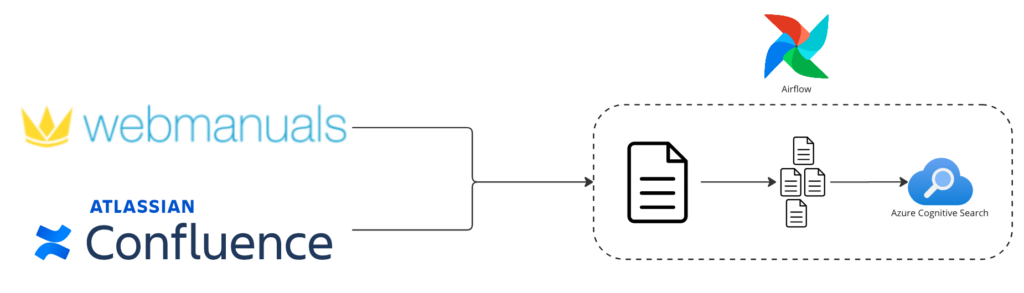
Document preparation is one of the biggest areas you can work on to improve the quality of responses for a LLM application like ours. The better the quality of information you can feed into the prompt, the better the responses from the LLM. Additionally, Azure Cognitive search offers a new feature called vector search [7] which is currently available in Public Preview. We found that search results were improved for our texts by using this feature. Therefore, we invested additional efforts to create embeddings with an embedding model from Azure OpenAI Service [8] to prepare our texts for vector search.
Building a chat on top of our documents
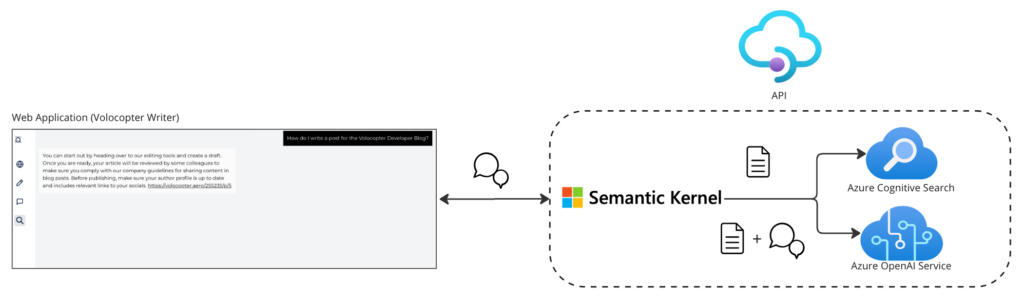
For the user interface of the chat, we've leveraged our design library [9] to include the necessary components so the user can have a Q&A session with the LLM. For every step in the conversation, the chat interface calls our search API using the content of the overall conversation as payload. For processing the API request, we use Semantic Kernel [10] to put the interaction with Azure Cognitive Search and the LLM provided by Azure OpenAI Service into action.
Overall, each request is processed with the following steps:
- Search for relevant document sections in Azure Cognitive Search with the user's question as the search term
- Feed this information as context into the prompt for the LLM along with the user's question
- Return the response including the source document links as citation
- For follow up questions, first let the AI model summarize the conversation as a search term
Once this chain of interactions with Azure Cognitive Search and Azure OpenAI Service has run successfully, the user will receive an answer to their question based on the context that was retrieved from our internal documentation along with citations.
Conclusion
Creating a LLM application with Azure OpenAI Service has made this whole task much easier than ever before. In the past, creating such an application would have been a time-consuming and complex process that would have required significant technical knowledge. Now, with Azure OpenAI Services, and leveraging our existing platforms like our design system, our developers can quickly and easily integrate a LLM into their application without having to write much code or acquire a lot of knowledge about LLMs in general. With this change, generative AI has become far more accessible for many enterprises and teams. This newfound accessibility is great because it will not be the LLM alone that revolutionizes the way we work. Instead, it will be the clever integration of an LLM into other applications that will unlock the anticipated productivity gains.
We hope that this post has provided you with some useful insights on how to create a secure environment that can leverage the power of LLM search through the use of Azure OpenAI Service and Azure Cognitive Search. All in all, we believe that we've just touched the surface of what is possible with this new set of tools. We are excited to see how our users explore the application and provide feedback to help us further develop this platform. So, stay tuned, there might be some new blog posts on the horizon.
Featured Image by Gabriel Sollmann on Unsplash
References
